
In Defense of Crusty Old Swiss Army Knives
I’m a fan of crusty old knives.
There’s a cold familiarity to them; you know what they’re good for and what they’re not, and despite their age, they remain largely the same as how you left them. In software, there aren’t a lot of tools that are allowed to get old. I feel like the default state is just a drop-off into obscurity.
But Django got old! Its twentieth birthday is almost here. I suppose that means Django has entered adulthood now, though 20ish years in software probably puts it more toward seniorhood than anything. When I stare at a CRUD-style use case, Django remains my default impulse. With the rise of stripped-down JS frameworks like HTMX, I thought it’d be exciting to pull out the crusty knives, sprinkle in some new JS goodness and explore the landscape. What follows in this article are my thoughts and lessons along the way. Enjoy!
A brief set of links for the busy:
So what are we building?
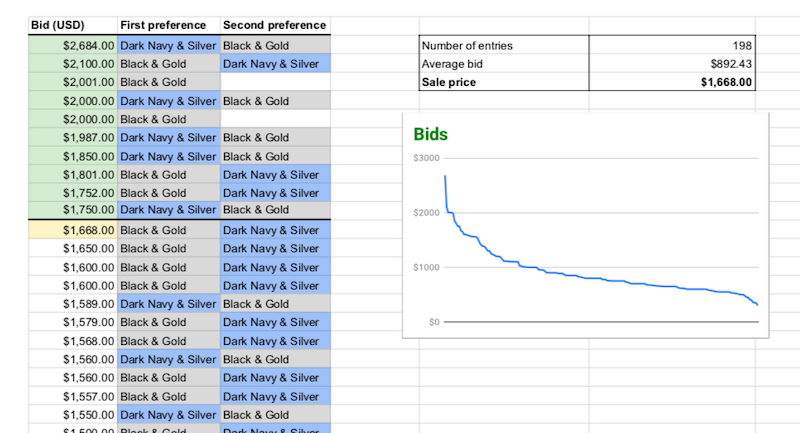
In 2019, Kevin Lynagh applied a unique style of auction to sell a small run of unique mechanical keyboards: https://kevinlynagh.com/notes/pricing-niche-products/. In doing so, this auction provided tons of information about the demand curve for these keyboards and helped make decisions about how to sell the keyboards moving forward.
Kevin used a Vickrey Auction.
These auctions work like this:
- You have ten keyboards to sell
- You ask all interested bidders to submit a bid with what they would be willing to pay for a single keyboard
- When the auction ends, the top 10 bids pay the 11th highest bid’s price.
I thought this was super clever.
I’m very interested in building and selling small runs of weird electronics. A lot of hands-on effort is required to make this stuff, and often you are very limited in how many of them you can build. Ambitiously, I thought it’d be useful to apply if I ever made something interesting enough for a bunch of people to want to purchase. (One can dream)
More concretely, this would be a perfect use case to explore ideas about Django & HTMX and how to build classic CRUD-style applications.
I started by whipping together some rough user flows and wireframes, which you can see here. This documentation helped me focus on the tasks before kicking things off and diving into development. I used mermaid for the little flow charts and balsamiq for the wireframes. These docs were rough and needed lots of detail, but it was enough to get moving.
In this article, I’ll focus on two core model objects, a Bid and an Auction. Sellers create auctions, and buyers create bids. At some point, the auction finishes, notifications are sent to all involved people, and the seller has a nice bit of data to understand how to price their products in the future.
Standing up the basics, views, templates, routing, ORM, admin
I think Django really shines in its fundamental ideas. In a nutshell, you have:
- Views, which are responsible for rendering a template with some data
- Templates, containing your markup
- Models, which represent some set of related data and functionality
- URLs, the “table of contents” for your application, declaring where to look for request-handling logic
In this basic functionality, Django does a great job. Templates are nicely composable and inheritable, giving you a lot of flexibility in dealing with markup. Either class-based or functional views handle requests, providing context to your templates and rendering them into responses. URL files clearly map out application routing and associated handlers. Django actively discusses how you can break up significant parts of your application into multiple applications, which can be a huge help as the complexity ramps up and you start to evaluate splitting up your system. An excellent ORM supports models, so you can interactively deal with your data through high-level functions. ORMs generally can be a bit polarising, and I do want to recognize that it’s helpful to keep an eye on the SQL generated for you. However, with some care, I find that using an ORM speeds up my pace and helps me concisely represent ideas.
Each of our auctions has a bid model, which looks like this:
class Bid(models.Model):
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
price = models.FloatField()
first_name = models.CharField(max_length=30, blank=True, null=True)
last_name = models.CharField(max_length=30, blank=True, null=True)
email = models.EmailField(blank=True, null=True)
auction = models.ForeignKey('Auction', on_delete=models.CASCADE, blank=True, null=True)
def __str__(self):
return f"Bid(id={self.id}) price: {self.price} for Auction(id={self.auction_id}) from {self.email}"
One of my favourite pieces of Django is its admin interface and integration with the ORM.
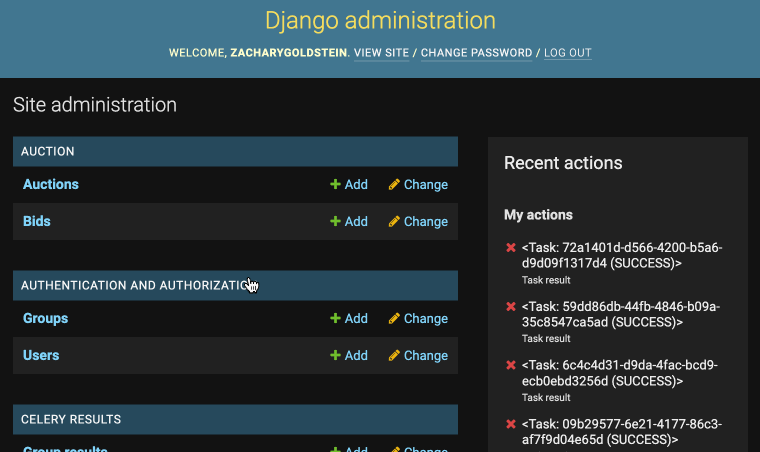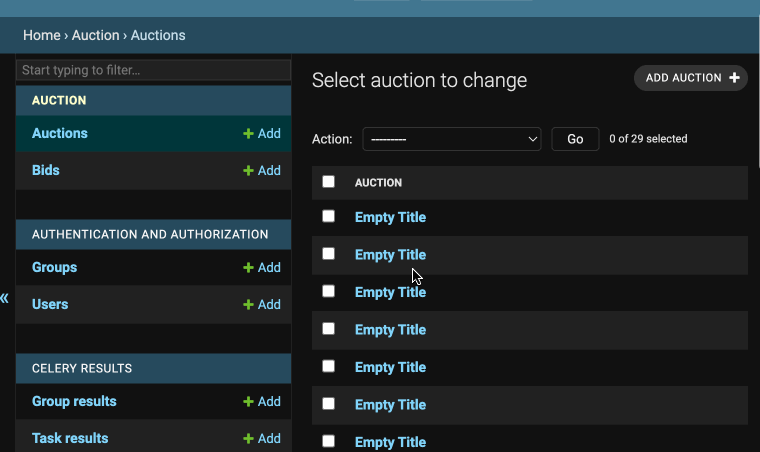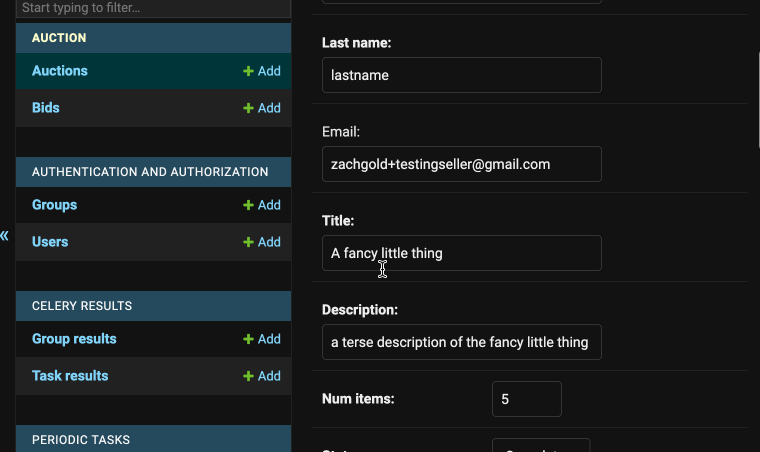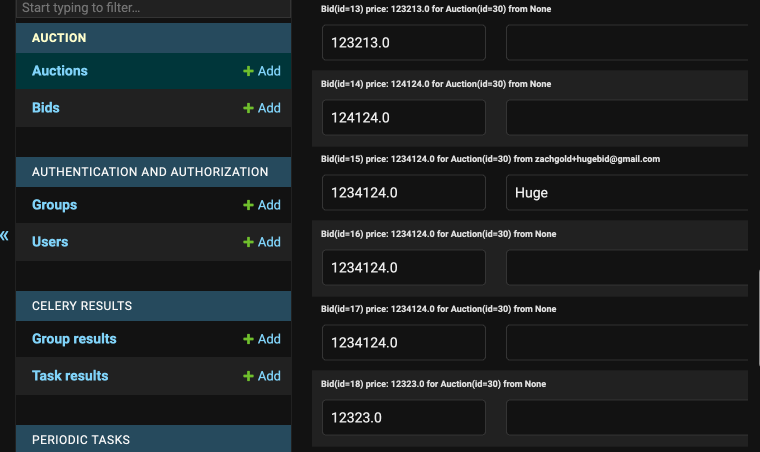
This works smoothly with your models; you only need to call register() with your model class for the admin interface to pick it up and give you this rich set of functionality for managing your data. In the past, I’ve looked to this as a starting point for non-technical people to interact with a Django application and, with a bit of iteration, built a functional set of tooling. There are other solutions like Retool, which offer low-code alternatives to create these sorts of internal tools. Unfortunately, I think these services poorly re-invent logic you already have through the Django ORM. The deep integration between django-admin and the ORM dodges possible inconsistencies between your application and external systems designed for internal tooling.
Another thing I love is being able to hack little administrative commands right into manage.py
class Command(BaseCommand):
help = 'Attemps to complete recently ended auctions and notify everybody'
def handle(self, *args, **options):
sent_emails: List[str] = []
self.stdout.write(self.style.SUCCESS(f"Attempting to complete auctions {Auction.have_completed.ids}"))
auction_sent_emails = complete_all_auctions_and_notify()
sent_emails.extend(auction_sent_emails)
self.stdout.write(self.style.SUCCESS(f"Attempted to complete auctions {Auction.have_completed.ids} and sent emails to {sent_emails}"))
This is a simplistic example, but it calls a service function, complete_all_auctions_and_notify, giving me a manual way to trigger this behaviour outside of its expected life as a periodic background task. I’ll dive more into services later in this article.
Keeping an eye out for future reusability with a Protocol class
The guts of this application are in the logic related to this unique style of auction. I decided to keep that logic together in one place in case I wanted to pull it out into a separate library in the future. The challenge here is that we have a Django model object in this application, which has its own specific set of functionality. So how do I remove any dependencies to Django here and make it more generic? The answer I explored was a Protocol class.
from typing import Protocol
class BidProtocol(Protocol):
price: int
id: int
To use this, I type the input of my functions:
def calculate_average_bid(bids: List[BidProtocol]) -> float:
return fmean([bid.price for bid in bids])
Protocol classes are great b/c it lets us specify inside this vickrey.py file that we have a specific interface required for the objects getting passed in without coupling to any particular way of fulfilling that interface. This approach is technically called “Structural Subtyping” and feels like an interface in Typescript. The BidProtocol fits our Django model object, allowing for more generic use cases. We could just as easily specify a dataclass and use the functionality without any knowledge of Django.
@dataclass
class GenericBid():
price: int
id: int
Earlier Python versions introduced abstract base classes, which would be one alternative here. We would make our input to the calculate_average_bid() function extend from an abstract base class (abc) we would create. The challenge is that we have to make the base model object inherit from this abc. I opted to avoid this. Mucking about with the inheritance of a Django base object didn’t feel like a great way to use generic logic like this.
The major consequence of this approach is that you’re losing a lot of the advantage of using an ORM and need to brute force operations over raw data. In this example, that means retrieving all bids and manually sorting and filtering, whereas using the Django ORM, we can use .filter() and .order_by(), which end up with more efficient queries.
UI - It’s a new world
Django predates Jquery. It’s a very crusty knife.
My feeling on the last 20 years of web development is that it’s been dominated by the rise of Javascript as the lingua franca of the internet, driven in part by increasingly sophisticated methods of manipulating data and the DOM. Most recently, this is through React, which seems to act as a gravity well that all engineers working on the web must pass through at some point. I think React’s reputation here is well-deserved; it’s an incredible achievement and offers a productive, flexible set of tools for the frontend web.
Despite the sophistication of these tools, I increasingly think this might be just too much tooling. In this toy application, we are looking at the classic CRUD-style use case with a sprinkling of dynamic functionality. I wanted to explore how things would feel if I dodged a JS-related build altogether.
As an aside: I’d recommend also reading Sam Eisenhandler’s article about abstractions, along with links to some related reading: https://samgeo.codes/layers-of-abstraction/. I profoundly agree with a major point in the article: “we should aspire to understand the benefits and costs of the abstractions that we build on top of”.
Moving away from React, a stripped down library called HTMX lets you add attributes to DOM elements for dynamic behaviour without writing JS. I wanted to give it a shot in this application and learn more about what it looks like in the context of a Django application. So I used it in a few places:
Auto-updating fields when creating a new auction
<sl-input name="title"
placeholder="{{auction.title}}"
size="large"
class="title-input text-2xl font-bold"
hx-trigger="keyup changed delay:500ms"
hx-vals='{"id": {{auction.id}}}'
hx-put="/auctions/{{auction.id}}/"
hx-headers='{"X-CSRFToken": "{{ csrf_token }}"}'
hx-target=".title-name">
</sl-input>
Our button to create a new bid for an auction
<sl-button
variant="primary"
hx-trigger="click"
hx-include="[name='bid-value'], [name='auction-id']"
hx-post="/bids/create"
hx-headers='{"X-CSRFToken": "{{ csrf_token }}"}'
hx-target=".bid-confirmation">
Place Bid
</sl-button>
Get stats about an auction for sellers, polling for updated stats every second:
<div
class="mt-10 grid grid-cols-1 gap-x-6 gap-y-4 sm:grid-cols-2"
hx-get="/auctions/{{auction.id}}/stats"
hx-trigger="every 1s"
hx-indicator="#spinner"
>
<sl-spinner id="spinner" style="font-size: 5rem; --track-width: 10px;"></sl-spinner>
</div>
Overall using HTMX was pretty painless and fit in quite nicely. When and why to use HTMX is outlined in a fantastic essay here. I’d advise folks to read this material to understand if HTMX makes sense for your use case. In the context of this application, there were a few scenarios where it felt like I bumped into its limitations:
For sellers to manage auctions, there are a set of tabs with the auction title above it. In one of those tabs, we can edit the auction. When doing this, we want to use the response to update this edit auction page and the auction title above all the tabs. With HTMX, I can use hx-swap to swap the response markup into multiple elements, but you need the response markup to make sense in all places you’re swapping it into. What do you do if you want it to be a header in one place and feedback text in another? Even worse, the auction edit page is a reusable template. If we include it on another page and it attempts to swap an element that doesn’t exist there, what then? Generally, this all feels like a code smell to me. Alternatively, I could poll for updated data in one place and keep the hx-swap target close to the element triggering the request. Ideally, I’d remove this “update in many places” requirement altogether.
In the future, I’d consider more involved JS tooling if I have hard requirements involving lots of dynamic behaviour. In this application, that looks like multiple, different UI updates triggered off a single request. I’d focus on more rigorous state management solutions like redux or mobx. In the redux ecosystem, there’s this idea of a thunk or saga, which gives you much better tools to manipulate a collection of state change side effects. I’d love to know if there are even more stripped-down alternatives to these libraries, as they can get pretty complex fast.
Django’s built-in abstractions to work with forms felt quite clunky. If you want to avoid page refreshes and build more immediate feedback into your forms, you’ll need to rethink the Django way of doing this and start building your own layer on top. On the login/registration page, I noticed this challenge. I wanted something basic to show indicators if the input was invalid (like a username conflict). Still, the built-in request handlers expect error feedback through session data. So I think there’s an opportunity for an abstraction that’d act as a quick way to use HTMX with forms, generating any necessary validation endpoints on the Django side.
Tailwind and whack-a-mole styling
I have seen so many terrifying cycles of endless whack-a-mole styling with CSS. It always begins with the best intentions, a style or two for the nav, a couple for the footer, and a few more for the primary bucket of content. Rinse and repeat for the dozen or so main pages of your application. Then the moles poke their head up, “let’s rework this into two columns,” “how about a new layout for this card,” and “these colours don’t feel right.” Dutifully whacking away, the team fixes every little thing one by one, but regressions start to appear and fixing the regressions causes more regressions. It can just be endless.
I think many people reach for utility frameworks like Tailwind because it bakes in many hard-to-remember minutiae about how to work with CSS. While it’s great for this, I think the real strength is that you’re thinking with the reusable patterns of a design system. These patterns fill a gap that is more granular than the components of a complete UI toolkit and more coarse than basic CSS rules. It is no magic panacea, but at least you have more reusability in your mind. I’m not a styling expert, but my limited experience has been that I usually wish I had started using these utility frameworks (or, more broadly, a design system) sooner. I won’t get into the nitty-gritty of using Tailwind here, but their docs are excellent and step you through usage. Despite the price, I’m a particular fan of the TailwindUI set of templates & components. I see it as a significant upgrade over the more traditional Bootstrap.
In the Django ecosystem, there’s the django-tailwind extension, which streamlined things a lot. Tailwind has some sophisticated ways of minifying and bundling only the styling you end up using, but unfortunately, it’s a bit of tooling that needs to get run. django-tailwind adds a very convenient command to watch for changes and run this tooling:
python3 manage.py tailwind start
Building off UI libraries
At some point, I acquiesced. I wanted just a bit more interactivity but didn’t want to roll my own components. For the seller’s auction detail page, I thought it’d be nice to have a few little tabs you could click between without triggering a full page refresh. And when creating or editing an auction, I thought having some nicer input fields would be cool. I couldn’t help myself from expanding the scope. A tale as old as time.
There are a ton of really well-built JS UI libraries out there. The rabbit hole of options runs very deep, with many different approaches and philosophies underpinning them. I am in the web components camp. You might be in the react camp. That’s ok! I went with https://shoelace.style/ as my UI library de jour, mainly because of its use of Lit, a web components based library I know and enjoy.
Shoelace components are excellent, and I’d recommend people check the library out. In this application, I quickly cherry-picked the components I needed via their CDN, added them to my header and immediately started using them.
Using a shoelace input component with HTMX and Django looked like this:
<sl-button
variant="primary"
hx-trigger="click"
hx-include="[name='bid-value'], [name='auction-id']"
hx-post="/bids/create"
hx-headers='{"X-CSRFToken": "{{ csrf_token }}"}'
hx-target=".bid-confirmation"
>
Place Bid
</sl-button>
The big challenge I could not resolve was making the shoelace components look consistent with Tailwind styling. A big strength of webcomponents is the strong encapsulation you get through the shadow dom. A downside of this is that application-wide styles become more challenging to apply. I was not able to quickly find a clean way of using tailwind utility classes with shoelace components. Shoelace has a documented way to theme its components, so I think that’s probably the first thing to investigate.
Moving past HTMX toward islands
After exploring Django with HTMX, I continue to wonder how I could tackle increasingly dynamic UI challenges without fully committing to building a SPA. I’m particularly excited about the islands architecture, which builds on the strengths of web components, with all their encapsulation and isolation. Some initial thought pieces on the approach are from Etsy’s frontend architect Katie Sylor-Miller in 2019, and Preact’s creator Jason Miller here. I think the most public implementation of it right now feels like Astro. The core idea behind the island’s architecture is that you have a static page with little “islands” that contain non-trivial dynamic behaviour:
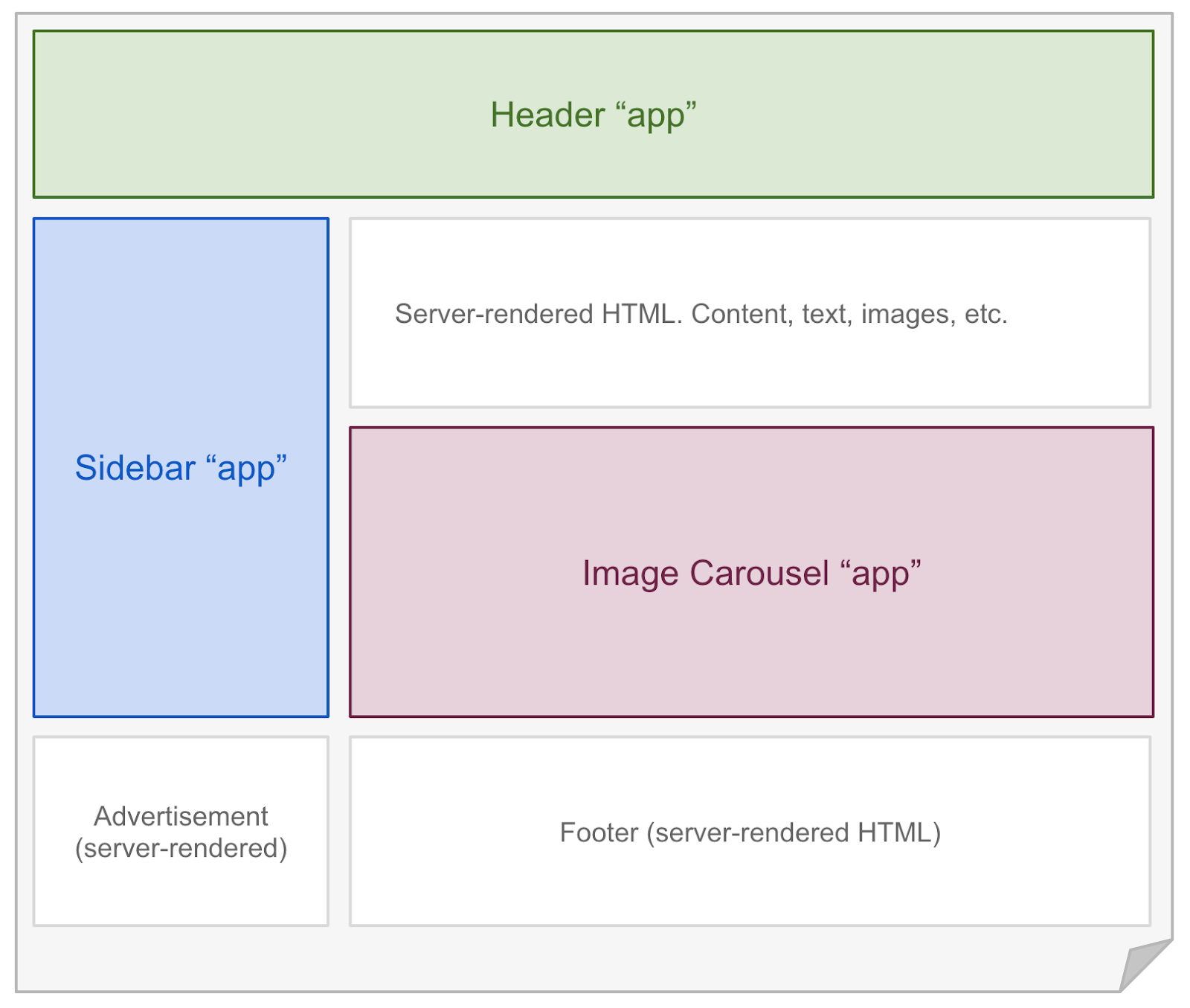
Combining well-isolated web components with all the features of frameworks like Django makes a ton of sense to me, and I’d love to explore it further in the future.
Background Tasks & Celery
In this application, Auctions have an end date, after which several things must happen:
- The Auction is marked as complete
- Email notifications are sent to the auction seller and all the people that submitted bids
This is a pretty classic background task. Periodically we want to scan for these recently ended auctions, then trigger this behaviour for each of them.
There are tons of options in the Django ecosystem for background tasks like this, with varying degrees of complexity and features. I chose one of the most popular libraries, Celery. It’s a well-built and maintained library with tons of flexibility. With a few extensions, django-celery-beat and django-celery-results, objects representing periodic tasks, schedules, and task results can appear directly in the admin interface, which is super convenient.
I struggled to get this going. One hangup was trying to get django-celery-beat to work. Eventually, I clued in that periodic tasks need to be created like other any other model objects instead of the convenience functions in the celery docs. In my [tasks.py](http://tasks.py) file, that looks like this:
schedule_min, created = IntervalSchedule.objects.get_or_create(
every=1,
period=IntervalSchedule.MINUTES,
)
PeriodicTask.objects.create(
interval=schedule_min,
name='Complete active auctions',
task='complete_auctions',
args=json.dumps([]),
start_time = datetime.utcnow()
)
Writing tasks within Celery is super easy, here’s what the complete_auctions task looks like:
@app.task(name = "complete_auctions")
def complete_auctions():
sent_emails = complete_all_auctions_and_notify()
results = f"Attempted to complete auctions {Auction.have_completed.ids} and sent emails to {sent_emails}"
return results
Warning: As written above, this isn’t a rigorous way to do this. Errors, warnings, etc., could all be better handled, and the final results object should contain much more information.
I used Redis as the broker and the Django DB as the backend (enabled by django-celery-beat). Just following along with the docs; this worked together nicely. I love the deep flexibility of Celery here; it was great to know that I could migrate to SQS as the broker in the future. That said, I would have loved some more accessible defaults with Django; it wasn’t clear how I could use the Django DB here as the broker, which would have been a much simpler setup to get things off the ground.
I’m surprised that background jobs are not baked into Django in some minimal form. I might be unaware of how to do it with Django, and if so, apologies! Overall I see background tasks like this as a critical piece of the puzzle for many applications, and I’d prefer to see the functionality available as a first class thing.
Another excellent alternative for doing periodic jobs that I’ve used and would recommend is APScheduler. It’s not as well integrated with Django, but I think it’s a much easier system for doing background tasks. Outside of a Django application, it’s my go-to library for managing periodic jobs.
Email is easy!
Sending emails with Django is as easy as this:
seller_text = f"""
Your auction, {auction.title}, at {auction.absolute_url} is complete.
There were {auction.bid_set.count()} bids
The winning bid price was ${auction.winning_bid_price:.2f}, and average winning bid was ${auction.winning_average_bid:.2f}
"""
send_mail(
'Your auction for {auction.title} is complete',
seller_text,
settings.EMAIL_FROM_ADDRESS,
[auction.email],
fail_silently=False,
)
When standing things up locally, it’s super useful to run smptd to have an easy little mail server to test with:
python -m smtpd -n -c DebuggingServer localhost:1025
Moving past smptd, you can quickly pop in many transactional email providers, like SES, Mailgun, SparkPost, etc. One thing I didn’t explore in much detail here is making the emails themselves actually look good since it’s a whole pandora’s box. Generally, you want to treat email as just another view and render it like standard markup. Unfortunately, there’s a bit more complexity in the myriad ways different devices and email providers decide to render your email. It’s critical to test out how an email looks; some good tools are Litmus
and Email on Acid. In the past, I’ve found the most success in keeping emails as simple as possible, with as little layout as possible.
Where do you put the non-view, non-model stuff? Enter Services
So we can send emails and have a periodic task to trigger it, but where does the logic to tie it all together belong?
Generally, a big trend in Django applications is to have “fat models,” where your business logic lives as methods on model objects. These models are “fat” because the model classes keep gobbling up the complexity as you add more and more functionality. Accompanying this are “skinny views” that usually call model methods and add information into a context object used to render the response.
Over time this gets wild. As the functionality gets increasingly complex, you start to see all sorts of coupling between your models. It gets harder to test and difficult to understand. I look to model managers and service functions to mitigate this problem, and I generally start reaching for them early in development.
Often you want to build functionality at the table-level, acting on some subset of model objects. A Model Manager nicely encapsulates this sort of behaviour. Here’s an example implementation of Auction.active.get_average_num_bids(), which returns the average number of bids for every active Auction in the system:
class ActiveAuctionManager(models.Manager):
def get_queryset(self):
return super(ActiveAuctionManager, self).get_queryset().filter(
status=Auction.StatusChoices.ACTIVE
)
def get_average_num_bids(self):
auctions = self.get_queryset().all()
return fmean([auction.bid_set.count() for auction in auctions])
You can set a model manager right on the model, so you have access via something like Auction.active
class Auction(models.Model):
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
objects = models.Manager()
active = ActiveAuctionManager()
...
In other situations, you want a method that will do several somewhat unrelated things. In this application, a good example is the chain of events we want to occur after an Auction completes. It’s a bit simplistic, but we essentially want to mark the auction complete and send a bunch of emails. I call logic like this a “service” and place it in a service.py
def complete_auction_and_notify(auction:Auction) -> List[str]:
sent_emails = []
if not auction.email:
print(f"No email found for seller auction {auction.id}, returning")
return sent_emails
seller_email = send_winning_bid_email(auction)
sent_emails.append(seller_email)
for bid in auction.winning_bids:
if not bid.email:
print(f"No email found for bid {bid.id}")
continue
winning_email = send_winning_bid_email(auction, bid)
sent_emails.append(winning_email)
for bid in auction.losing_bids:
if not bid.email:
print(f"No email found for bid {bid.id}")
continue
losing_email = send_losing_bid_email(auction, bid)
sent_emails.append(losing_email)
auction.complete()
return sent_emails
This functionality is called from a background task but could just as easily be triggered off a request or manual command.
I like to give my business logic its own layer like this for several reasons:
- We can keep our model objects & managers focused on manipulating data
- The way we use models & model managers is now isolated in this service, and we can test it independently
For more details:
- Kimmo Sääskilahti wrote an excellent article describing service functions here: https://dev.to/ksaaskil/tips-for-building-a-clean-rest-api-in-django-2pae.
- Outside of the Django context, this approach is well documented by Damir Svrtan and Sergii Makagon from Netflix: https://netflixtechblog.com/ready-for-changes-with-hexagonal-architecture-b315ec967749. The article outlines their use of hexagonal architecture, which is roughly what we’re doing here.
The ugly auth story
Standing up login and registration flows was a huge pain
A big takeaway from this exercise has been the feeling that it’s a bit challenging to use the built-in authentication system, specifically the login & registration flow. In the context of the admin interface, these flows work out of the box, but standing up a more user-facing flow felt unreasonably involved.
I think authentication and authorization are also just hard problems. And I don’t think many people feel that this is the case. It’s often taken for granted that some login/logout functionality will await you when you use a big, feature-rich full-stack framework. These systems have many moving pieces, like permissions, password management, forms integrated into login/logout views, etc.
So I set out to create a rough login & registration UI & flow that looks like this (from tailwindUI), minus the social login buttons and with a second button to register instead of sign in:
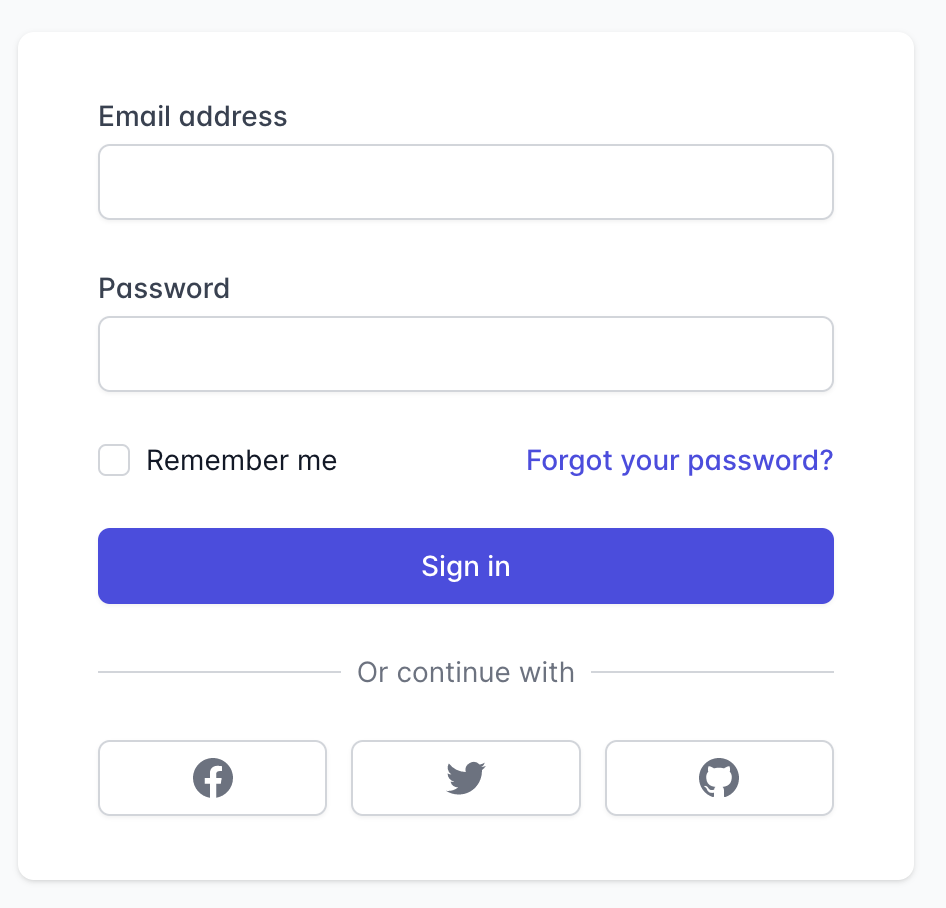
I found this challenging.
The documentation felt impenetrable here. I could see a set of auth docs referenced in the docs here, and from there I could see an example of how to either authenticate() a previously logged-in user or login() a new one. What I wanted was to be spoon-fed a custom login/signup example. Instead, it took me time to piece together a login view and the necessary markup to trigger it.
For a real-world implementation, I’d prioritize moving beyond the built-in auth systems as early as possible. The dominant library to build out these systems seems to be django-allauth, which looks like a pretty well built & documented library.
Deploying & Operating
There is some excellent writing about how to deploy and operate Django. Part of Django’s strength is that many people have embarked on the journey and documented their strategy. After doing this a few times, I also have a few opinions. I want to preface this section by saying that simplified deployment platforms like Heroku or Fly.io are excellent and probably the best-supported way to arrive at a reliable deployment quickly. I’ve generally been building applications with somewhat unusual deployment constraints and, as a result, built up a bit more of a hands-on approach.
Before any customer-facing deployment, I often use ngrok (https://ngrok.com/) for quick demos and feedback. ngrok is fantastic; it instantly opens up a public tunnel that anybody can use to interact with your application.
Past ngrok, the most basic solution I use is to ssh into an EC2 instance and manually set up the application. Then, to run it, I’d open up a session via screen , run [manage.py](http://manage.py/) runserver , detach and be on my merry way. If it went down, that’s ok! I’d ssh in, figure out what died, and then restart. Nothing too safe or reliable; I don’t want to fool anybody into thinking it’s a long-term solution.
Moving towards a customer-facing deployment, I move my manual setup into an ansible script that I can run locally. To get some basic restart functionality, I set up a systemd service (great tips on that here) for the process and any dependencies like redis. I also think about more convenient access to logs via papertrail and error management via sentry.
I think people underestimate how much performance you can get from a single machine and the benefits of vertically scaling. It feels fantastic to spin up tons of machines at once, but I’m not convinced that it should be at the top of priorities early in a project’s lifecycle. If you have a rigid constraint involving lots of scale, jump to a longer-term solution, but if it’s at all possible, try to interrogate scaling requirements early in development. I generally focus on getting things online for early feedback and only then tackle performance considerations. Generally, in a staggered way, ideally with real data about how the system you’re building is being used. A couple of strategies I’ve used that can pay off early on:
- Cache content in a CDN. This and tons of frontend tips from the sentry team: https://blog.sentry.io/2022/08/16/django-improvements-part-3-frontend-optimizations/
- Cache wherever you see bottlenecks. You can do it at the view level, site level, and template fragment level—lots of tips on this from the sentry and honeybadger teams.
- Start to get aware of your heavy DB queries. Think about how to better index the fields you’re interested in. Watch out for N+1 issues and use
prefetch_related(). If possible, also look at whether or not you can cache data via the low-level API,django.core.cacheand avoid queries altogether. - Make sure you’re pooling connections to the DB via something like pgbouncer
I think the idea of “scale” is more varied than the word implies. It’s great to spread load across a pool of instances, but often you get situations where some subset of users dominate usage or some geographic region begins to take off. In the past, I’ve seen a ton of success in formalizing the deployment with terraform and using that to make changes that affect a bunch of infrastructure quickly. This infrastructure-as-code approach feels critical when looking to do more complicated things, like setting up practical auto-scaling policies or sharding your system and splitting out traffic in Route53 based on user geography. Sometimes you even have business-level constraints that force you to run your system in specific AWS regions. Terraform is pretty crucial for that.
I think a strength of Django is that many of these ideas & techniques aren’t even Django-specific. It can have a bit of minor complexity around managing dependencies, but it’s otherwise a pretty predictable piece of software to deploy. Even better, there’s an almost 20-year history of people doing it and a pretty big paper trail online of different approaches to learn from.
Associated Goodies
Django’s got lots of goodies out there to make your life a bit easier. The ecosystem has provided many excellent extensions to help you build things. Here are a couple of my favourites:
- django-debug-toolbar has great tooling for understanding what’s happening when you render a page in your application. It appears as a sidebar menu with sections containing information about timings, cache, SQL, requests, etc. The standout feature here is the SQL section, with tons of information about all the queries the page triggered. It’s a fantastic way to understand what’s going on and an excellent tool to get a quick glimpse of any possibly problematic queries.
- django-extensions and within it, shell_plus. This autoloads all your models when you run Django’s interactive shell, saving time. As the number of models in your system increases, this becomes increasingly useful.
- Again inside django-extensions, the show_urls command is super helpful in quickly printing out all the different endpoints available.
What Now?
There are a lot of tools/SaaS out there to solve these same problems in more sophisticated ways. I don’t want to detract from the elegance of those solutions or the joy of piecing them together into something that perfectly fits your use case. By sketching out this solution, I’ve attempted to outline one possible path that has remained relatively durable after almost 20 years in addressing the concerns of a classic CRUD-style application.
Overall my feeling about Django is that, while it’s missing some cutting-edge features, it is still a reliable swiss-army knife that I can apply to a wide range of use cases. My perspective is that Django’s strengths are:
- It is long-term stable, and its performance is well understood.
- Views + ORM + admin does work well and can accelerate the development of CRUD applications
- The deep flexibility of Django lets me pick and choose where in the stack I’d like to allocate complexity based on the constraints I’m working within
- With the Python shell, Django’s ORM, django-admin, and it’s nature in Python, I can troubleshoot issues with confidence that I have access to all the different abstractions in front of me
- There are direct, vendor-agnostic pathways toward scaling
Is Django + lightweight JS the future? I’d probably say no. Through this journey, I’ve learnt a bit more about the limitations of this approach. I’d continue to use Django for straightforward CRUD View + ORM + admin situations, but if the use case could benefit from even moderate amounts of dynamic behaviour, I’d rethink the approach.
Looking forward, I’m excited to explore implementations of the island architecture and non-Python solutions that provide more integrated ways to sync updates to the browser without using lots of JS. Two interesting options are the Elixir language’s Phoenix framework and it’s liveview functionality and within the Ruby ecosystem, Rails hotwire.
Onwards!
A huge thanks to Andrew Healey, Sam Uong, and Myles Braithwaite for review on this article.