
Safely Carving Away a Snappy Golang Service from a Javascript Monolith
In a 2015 post, good ol’ Martin Fowler put it well:
Almost all the successful microservice stories have started with a monolith that got too big and was broken up (https://martinfowler.com/bliki/MonolithFirst.html)
So what does that process look like? In this post, we’re going to go on a little journey and carve away a high-performance service from a very simple node app. We’ll do load testing to verify our bottleneck, create a protobuf file to clearly communicate the service boundary, and then integrate a golang server implemented with an RPC library called Twirp. The general benefits of service-oriented architectures are a bit assumed here, but if you’d like to learn about those justifications in more detail, I’d highly suggest another Fowler article: https://martinfowler.com/articles/microservices.html#MicroservicesAndSoa
We’ll start with a node server that does something painfully simple. It has one endpoint that sums up random numbers:
const express = require('express');
const bodyParser = require('body-parser');
const app = express();
app.use(bodyParser.json());
app.use(express.json());
app.post('/Count', (req, res) => {
let sum = 0;
const timesToIterate = req.body.times;
for (var i = 1; i <= timesToIterate; i++) {
sum += Math.round(Math.random() * 100);
}
res.send(`Counted to ${sum} \n`);
})
app.listen(3000, () => console.log('BaseApp app listening on port 3000!'));This is our representation of a monolithic service, so indulge me while I imagine this toy app as if it was a huge system with all the usual moving pieces. Let’s say that this calculation is eating up our server performance, and we want to build out a separate system that’s engineered to solve only this problem in a very efficient way. It’s really important to understand that CPU performance is one of many reasons to carve away a service. For us here, it serves as a really great way to illustrate how the system is going to change, but generally, you’ll want to look at a whole ton of other constraints.
Some are technical, like memory usage, network throughput, or file I/O, while others could be purely social. Sometimes the most effective way for a lot of developers to work well in parallel is to separate them into smaller, service-focused groups where you establish clear boundaries between them and domain-specific targets.
So the first step here is to really understand your bottlenecks. We’ve created an artificial one in the form of a CPU intensive task, summing up random numbers. Before we get too far, let’s do some quick load testing to get an idea of what our performance looks like. We’ll be using a tool called artillery (https://artillery.io) in this post to do our load testing.
It’s a node script, so we npm install it:
npm install -g artilleryOne-off quick tests can be done with the quick command:
artillery quick --count 10 -n 20 https://artillery.io/In our app, we need to post with some data, so we’ll create a config file called baseAppLoadTest.yml
config:
target: "http://localhost:3000"
phases:
- duration: 10
arrivalRate: 20
scenarios:
- name: "Count random numbers"
flow:
- post:
url: "/Count"
json:
times: 10000000Here we’re just hitting a local service, but in the tests shown, I’ve actually spun up two aws instances within the same AWS region & AZ - a beefy one with a few cores where we are running our system and another small instance from which we’re executing this load test. This avoids inconsistent results when issuing requests from a congested network like a coworking space. I learned this the hard way, but if you crank up the RPS here (arrivalRate), it’s possible to knock your network offline.
I also run htop (which is just a fancier version of top) to visualize how we’re utilizing the cores on this instance.
Running the node app and load testing:
artillery run ./baseAppLoadTest.ymlRPS sent: 4.64 Request latency: min: 232.7 max: 32857.7 median: 16351.4 p95: 31296.4 p99: 32614.5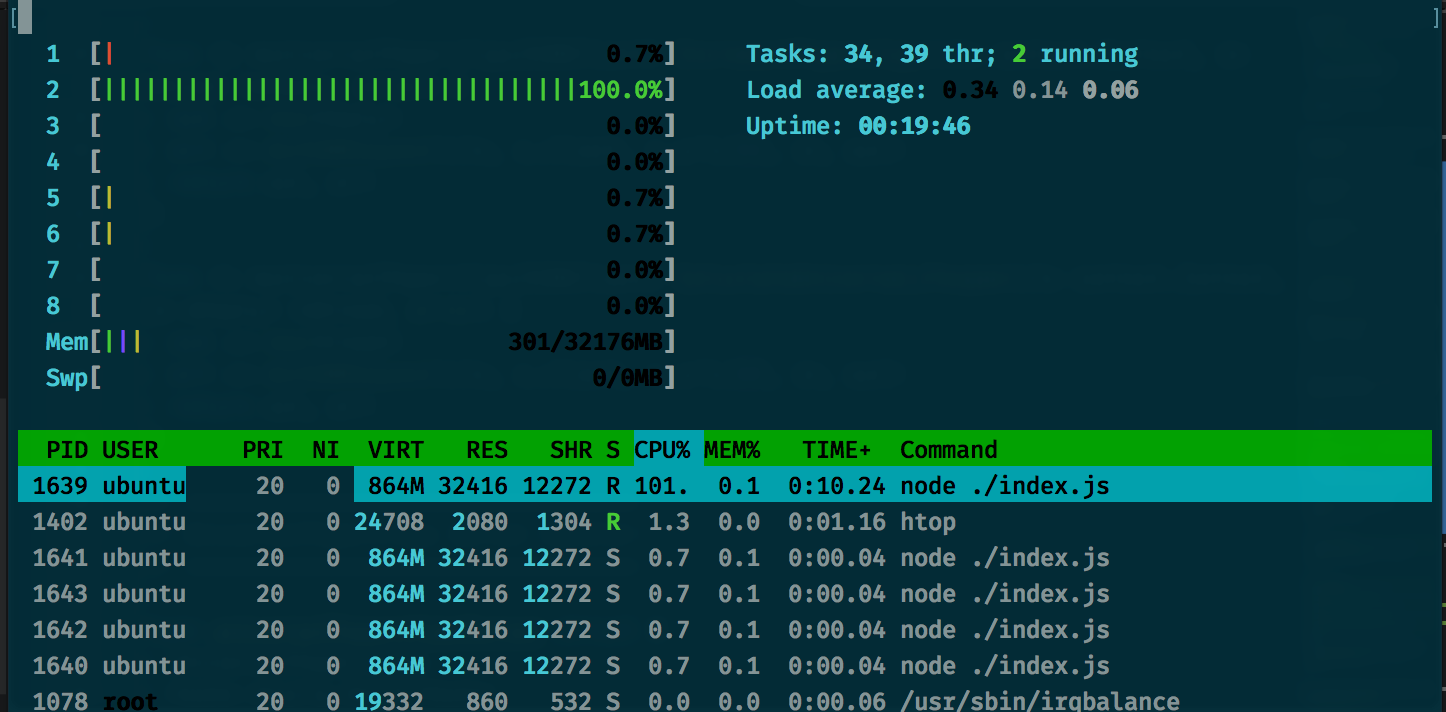
At high CPU loads, the Node.js event loop competes with the V8 garbage collector over CPU time, which wrecks our performance. If we tune down task intensity to {times:1000000}, we see that performance is actually pretty decent when we’re not nuking a CPU:
RPS sent: 20.04 Request latency: min: 26.5 max: 37.5 median: 27.1 p95: 28 p99: 30.1So we have our bottleneck.
To tackle this world-altering problem, we’re going to create a go service using an RPC library called Twirp and protobuf, a transport protocol. But why go?And why bother with this at all?
First off, our main strategy here to improve performance is going to be leveraging better concurrency primitives to let us fully utilize all of the CPU cores on a larger system. Node, python, and ruby all use a GIL to make the most out of a single core, but this GIL also means that there’s quite a bit of additional complexity to write safe, concurrent software. We’re going to use go because of its simple approach to concurrency and its strong profiling and benchmarking tools. We won’t dive into those tools here, but it’s worth mentioning that pprof and go-torch in particular are wonderful ways to understand your program better.
So could we use Rust? Elixir? Erlang? Yes! But today, go is our choice du jour on our journey towards service-oriented nirvana. We’ll be using an RPC library called Twirp (similar to gRPC but simpler) to do this. See this associated post for another example of writing go code to do this: https://x-team.com/blog/golang-rpc-twirp/
Follow the installation instructions for twirp and it’s protobuf dependencies here: https://github.com/twitchtv/twirp#installation
We’ll start by writing a protobuf file that describes our new service and the messages it uses.
syntax = "proto3";
package twirp.carved;
option go_package = "rpc";
// Carved service counts numbers very quickly.
service Carved {
rpc Count(Times) returns (Sum);
}
message Times {
int32 times = 1; // must be > 0
}
message Sum {
int32 Sum = 1;
}Using twirp, we’ll generate stubs for this service and place them in the rpc folder.
protoc --proto_path=$GOPATH/src:. --twirp_out=./rpc --go_out=./rpc ./carvedService.proto
Our service implementation looks like this:
package server
import (
"context"
"math/rand"
"sync"
"time"
pb "github.com/zachgoldstein/serviceCarving/carvedService/rpc"
)
// Server implements the UniversalPaperclips service
type Server struct{}
// NewServer creates an instance of our server
func NewServer() *Server {
return &Server{}
}
type countMutex struct {
mu *sync.Mutex
count int32
}
// CountWorker sums of numbers based on ints placed on the jobChan,
// adding them to a mutex-protected counter when done.
func CountWorker(count *countMutex, wg *sync.WaitGroup, jobChan <-chan int) {
r := rand.New(rand.NewSource(time.Now().Unix()))
for j := range jobChan {
sum := int32(0)
for i := 0; i < j; i++ {
sum += r.Int31n(100)
}
count.mu.Lock()
count.count += sum
count.mu.Unlock()
wg.Done()
}
}
// Count finds the sum of random numbers added together N times
func (s *Server) Count(ctx context.Context, times *pb.Times) (*pb.Sum, error) {
wg := &sync.WaitGroup{}
jobSize := 100000
numWorkers := 5
countMutex := &countMutex{
mu: &sync.Mutex{},
count: 0,
}
jobChan := make(chan int, 100)
for i := 0; i < numWorkers; i++ {
go CountWorker(countMutex, wg, jobChan)
}
numJobs := int(times.Times) / jobSize
if jobSize > int(times.Times) {
numJobs = 1
jobSize = int(times.Times)
}
for w := 0; w < numJobs; w++ {
wg.Add(1)
jobChan <- jobSize
}
close(jobChan)
wg.Wait()
return &pb.Sum{
Sum: countMutex.count,
}, nil
}Our implementation here uses a worker pool system to safely and concurrently sum random numbers. For a more detailed discussion of the mechanics here, see https://gobyexample.com/worker-pools. We’re using worker pools to control the degree of parallelism used in our program. It’s important to note that you can have too much parallelism, and creating excessive numbers of goroutines will cause the scheduler to have a tough time mapping them to OS threads, eating up performance. Here we use a non-trivial jobSize to make sure that each goroutine is doing a reasonable amount of work. Since we’re summing up numbers, we also have a mutex that’s properly synchronizing that summed value between many goroutines. We want to avoid waiting around on this lock, so the limited size of the worker pool here makes sure that the number of active goroutines using the same mutex is small and the time spent waiting for the lock is trivial.
As an aside, another great little trick is to provide a go-routine scoped seed for rand.Int31n(). By default, go uses a globally locked pseudo-random number generator, and at high load, you can lose a lot of performance in waiting for that lock. Using go-torch, we can see this here:
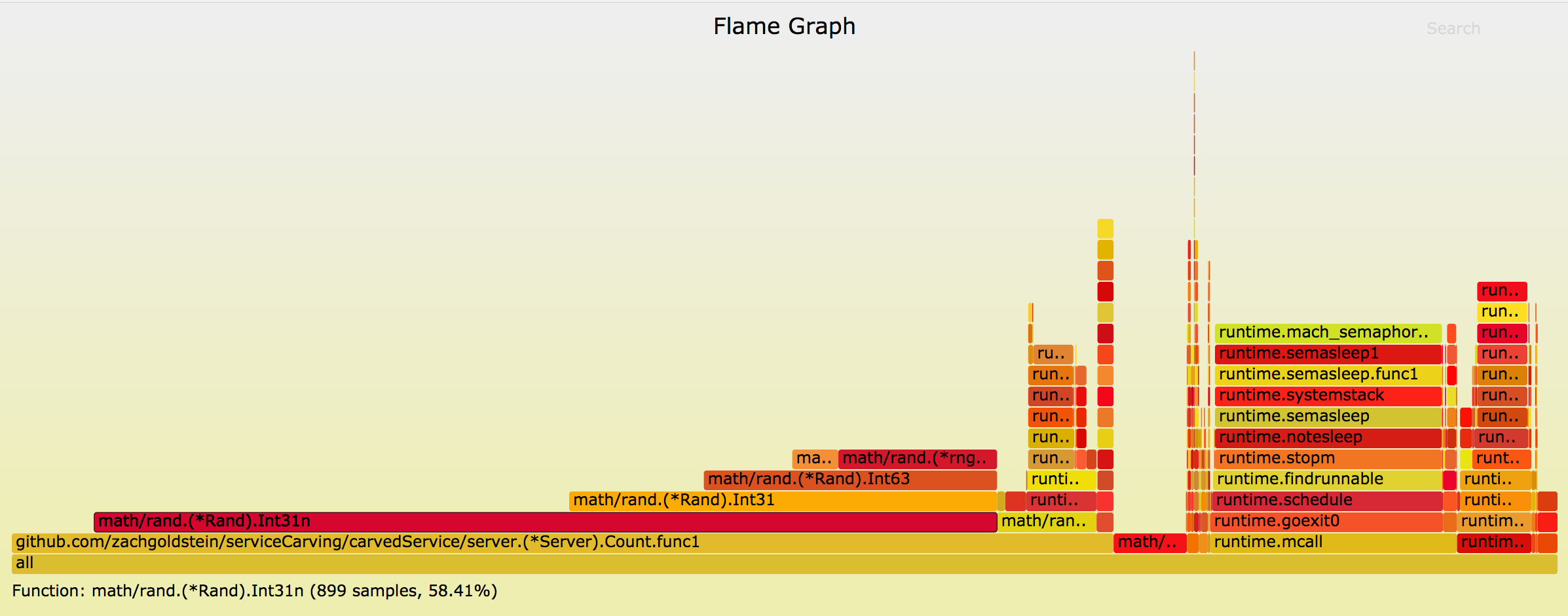
Instead, you can provide a seed that’s safe to use concurrently, which is what we do with:
r := rand.New(rand.NewSource(time.Now().Unix()))We use this implementation in our main like so:
package main
import (
"fmt"
"log"
"net/http"
"github.com/zachgoldstein/serviceCarving/carvedService/rpc"
"github.com/zachgoldstein/serviceCarving/carvedService/server"
)
func main() {
fmt.Printf("Superfast Counting Service running on :6666")
server := server.NewServer()
twirpHandler := rpc.NewCarvedServer(server, nil)
log.Fatal(http.ListenAndServe(":6666", twirpHandler))
}So how does this perform?
RPS sent: 19.16 Request latency: min: 41.4 max: 63.3 median: 42.6 p95: 44.6 p99: 47.1htop, we can see it’s running nicely across all our cores.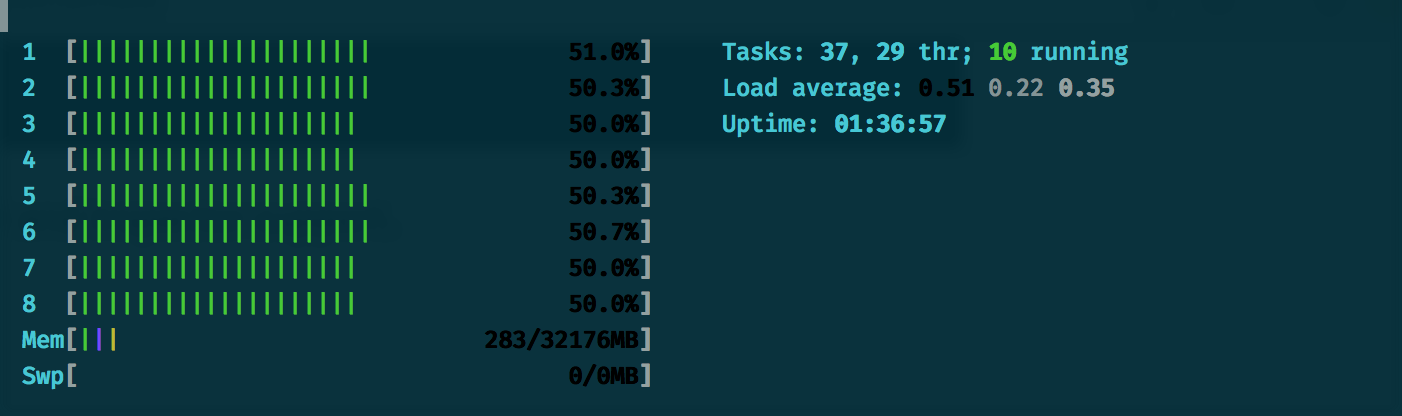
Now that we have a service that properly solves our CPU-bound bottleneck, we can integrate it back into our “monolithic” node app.
Bringing in protobufjs, our server now looks like this:
const protobuf = require("protobufjs");
const express = require('express');
const bodyParser = require('body-parser');
const request = require("request");
const app = express();
app.use(bodyParser.json());
app.use(express.json());
app.get('/', (req, res) => {
res.send('Hello World!');
})
function getSumBuffer(data) {
const errMsg = Sum.verify(data);
if (errMsg) {
throw errMsg;
}
const sum = Sum.fromObject(data);
return Sum.encode(sum).finish();
}
function processCount(requestData, callback) {
var times = Times.decode(requestData);
request({
method: 'POST',
uri: 'http://localhost:6666/twirp/twirp.carved.Carved/Count',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(times)
}, function(error, response, body) {
const buffer = getSumBuffer(JSON.parse(body));
callback(error, buffer);
});
}
function rpcImpl(method, requestData, callback) {
if (method.name === 'Count') {
processCount(requestData, callback);
}
}
app.post('/Count', (req, res) => {
carvedService.count(req.body, function(err, response) {
res.send(`Counted to ${response.Sum} \n`)
});
})
const root = protobuf.loadSync("../carvedService.proto");
const CarvedService = root.lookupService("Carved");
const carvedService = CarvedService.create(rpcImpl, false, false);
const Times = root.lookupType("Times");
const Sum = root.lookupType("Sum");
app.listen(3000, () => {
console.log('BaseApp app listening on port 3000!');
})So in a nutshell, our node server issues a request to the go service to do the heavy lifting in counting. A lot of the boilerplate you see here can be abstracted as your system includes more endpoints and messages. The meat of this logic is in processCount, where we do the serialization/ deserialization for our service, issuing an RPC request and returning a properly formatted result.
How does this perform?
### Carved System: RPS sent: 19.14 Request latency: min: 42.9 max: 56.4 median: 44.3 p95: 46.2 p99: 54So pretty well, despite the fact we’ve introduced a hop between the two servers. We’re also now operating across all cores: Happy times. Hope you enjoyed this adventure and picked up some useful tips to strategically carve away services in your system.
Originally published at x-team.com on March 12, 2018.